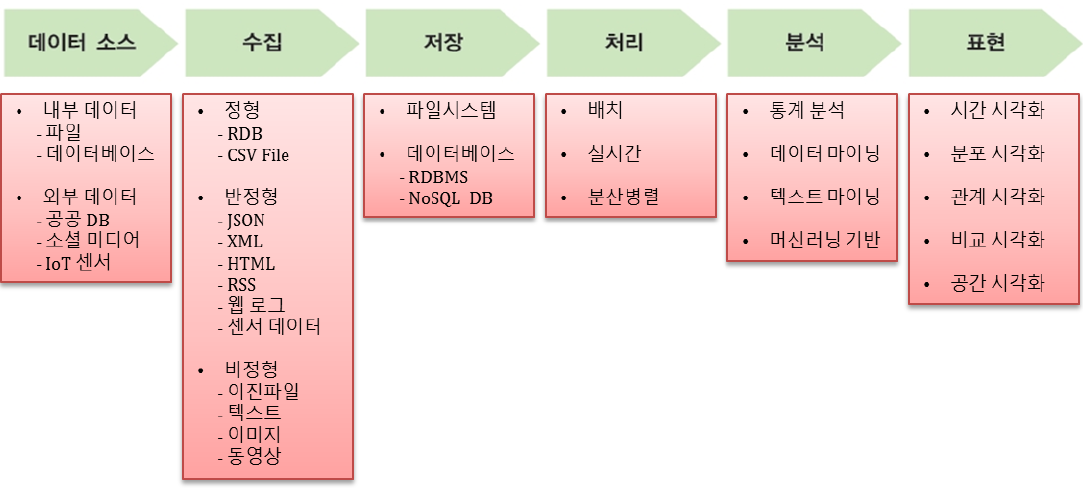
비정형 데이터 분석을 위한 기본 내용으로, 먼저 데이터 종류 3가지에 대하여 정리해 보고자 합니다. 빅데이터 분석을 위
한 데이터는 정형 데이터, 비정형 데이터, 반정형 데이터로 구분됩니다. 인간이 살아가고 있는 실제 세상에서 발생되는 여러 이벤트는 사람이나 사물을 통하여 데이터로 생성 되게 됩니다. 사물인터넷이 바로 그러한 실제 세상에서 발생되는 데이터를 수집하여 저장하고, 저장된 데이터를 가공 및 처리하여 다양한 서비스를 만들어가게 됩니다. 그러한 서비스들이 Home에 적용되면 Smart Home, 사무실에 적용되면 Smart Office, 공장(제조)에 적용되면 Smart Factory, 도시에 적용되면 Smart City, 헬스케어에 적용되면 Smart Healthcare 가 되는 것입니다. 데이터를 수집하기 위한 센서들이 각 영역에 설치되어 데이터를 수집하게 되는데 인터넷(네트워크)를 활용한다고 하여 Internet of Things라고 불립니다. IoT라고 불리는 것입니다. 이렇게 생성된 데이터는 대부분 반정형 데이터라고 불리면서, 빅데이터에 포함된다고 생각하면 되겠습니다.

빅데이터란 규모가 방대하고(Volume), 생성 주기가 짧고 빠르며(Velocity), 형태도 다양한(Variety) 대규모 데이터라고 합니다. (3V로 빅데이터의 특징) 또는, 빅데이터 생성, 수집, 저장, 처리, 분석하여 가치를 추출하고 결과를 표현하여 의사결정에 사용하도록 하는 기술을 의미하기도 합니다.
정형데이터는 일반적으로 관계형 데이터베이스, 엑셀파일에 저장되는 데이터이며, 반정형 데이터는 JSON, XML, HTML, RSS, 웹 로그, 센서 데이터 등으로 보면 되겠습니다. 비정형 데이터는 이진파일, 텍스트, 이미지, 동영상, 음성 등의 데이터로 보면 됩니다. 이러한 데이터를 데이터 소스에서 수집하고 분석을 위해 적합한 저장소를 선택하여 저장하며, 데이터에 대한 배치, 실시간, 분산병렬 등의 처리작업을 거치게 됩니다. 분석을 위한 전처리 작업이 이에 해당됩니다. 그리고 처리된 데이터를 통계, 데이터 마이닝, 텍스트 마이닝, 머신러닝, 딥러닝 등을 통하여 분석하고 이를 시각화 하는 절차로 이루어 집니다. 이러한 절차를 빅데이터 분석 전주기 라고 하는데요, 일반적인 SI 프로젝트와 비슷하게 방법론이 있습니다. 요구사항 수집, 데이터 수집, 데이터 저장/전처리, 데이터 분석, 데이터 분석 시각화의 흐름으로 이루어 지며, 각 단계에서 필요한 산출물 및 프로세스를 정의합니다.
1. 텍스트 데이터
텍스트 데이터의 유형에는 Book, News, Paper, Patents, Reports, Blog, Web Pages, Social Media 등 다양한 데이터가 존재합니다. 텍스트는 문자(Character)의 집합으로, 컴퓨터가 이해하기 위해서는 하나의 정해진 수로 표현됩니다. 문자는 아시다시피 코드셋을 사용하게 되는데요, ASCII 코드, Unicode, UTF-8 등이 있습니다.
- ASCII (America Standard Code for Information Interchange)는 미국 표준협회에서 국제적인 표준으로 정한 문자코드로 7비트를 사용하여 128개의 문자, 숫자, 특수문자 코드를 규정하고 있습니다. 실제로 하나의 문자는 0부터 시작하여 8비트로 저장됩니다.
- Unicode는 전 세계 모든 언어를 하나의 코드 체계로 통합하기 위해 만들어 졌습니다. 2바이트인 16비트로 확장된 코드 체계이며, 1995년 65,536자의 코드 영역을 언어학적으로 분류하였습니다. 국제표준화기구(ISO)에 상정 및 확정되었고 계속 수정 보완 되고 있습니다.
- UTF-8(Unicode Transformation Format 8-bit) 는 Unicode를 위한 가변 길이 문자 인코딩 방식 중의 하나로 Unicode 한문자를 나타내기 위해 1바이트에서 4바이트 까지 가변적으로 인코딩 합니다. Unicode는 모두 2바이트로 저장하다보니 저장소가 낭비되는 문제가 있기에, 특정 범위에 있는 문자는 1바이트로 표현하고 다른 범위에 있는(숫자, 영어가 아닌 다른 언어) Unicode 문자들은 3바이트로 표현합니다.
2. 이미지 데이터
이미지 데이터에는 화면을 구성하는 픽셀(Pixel:Picture Element = 화소)과 색상의 수를 고려합니다.픽셀은 화면을 구성하는 가장 기본단위로 이미지는 픽셀의 집합으로 표현됩니다. 각 픽셀은 Red, Green, Blue의 값을 적절히 배합시켜 색을 표현하게 되는데요 색상의 수는 픽셀당 할당된 비트의 수가 클수록 더 많은 색상을 표현합니다. 픽셀을 사용한 이미지를 비트맵이라고 부르며, 잘 아시는 .bmp, .gif, .jpeg 등의 확장자를 가지고 있습니다. 사실적인 표현이 가능하나 고해상도 이미지 일수록 파일의 용량이 증가하며, 작은 이미지를 확대하는 경우 픽셀의 각진 현태가 보입니다.
- 래스터(Raster) 그래픽은 픽셀 단위로 저장하는 방식으로, 화면을 확대할 때 화질이 떨어지며(계단현상) 파일의 크기는 해상도에 비례합니다. Painting Tool 이나 사진 편집도구에서 사용하는 방식입니다.
- 벡터(Vector) 그래픽은 점, 선, 곡선, 원 등의 기하적 객체 즉, 그래픽함수로 표현하는 방식입니다. 화면 확대시 화질의 변화가 없으며 일반적으로 파일의 크기는 래스터 그래픽 방식보다 작습니다. Drawing Tool에서 점, 선, 원, 다각형 등 기하객체 생성이나 일러스트레이션, 3D 그래픽, 애니메이션 등에 적합합니다.
손글씨 이미지도 마찬가지로 사람이 작성한 글씨를 입력받아 디지털로 변환하는 과정을 거치게 됩니다. 가로 28, 세로 28 총 784개의 픽셀에 저장하게 되며, 각 픽셀은 밝기 정도를 판단하여 0~255까지 등급을 나누게 됩니다. 결국 "숫자"를 기반으로 하여 데이터를 저장하게 되는 것입니다.

이미지 데이터를 이루는 각 행은 벡터(Vector)로 모든 행은 행렬로 표현이 됩니다. 그렇기 때문에 덧셈과 뺄셈같은 연산이 가능하며, 이를 활용하여 다양한 이미지 처리를 수행하게 됩니다.
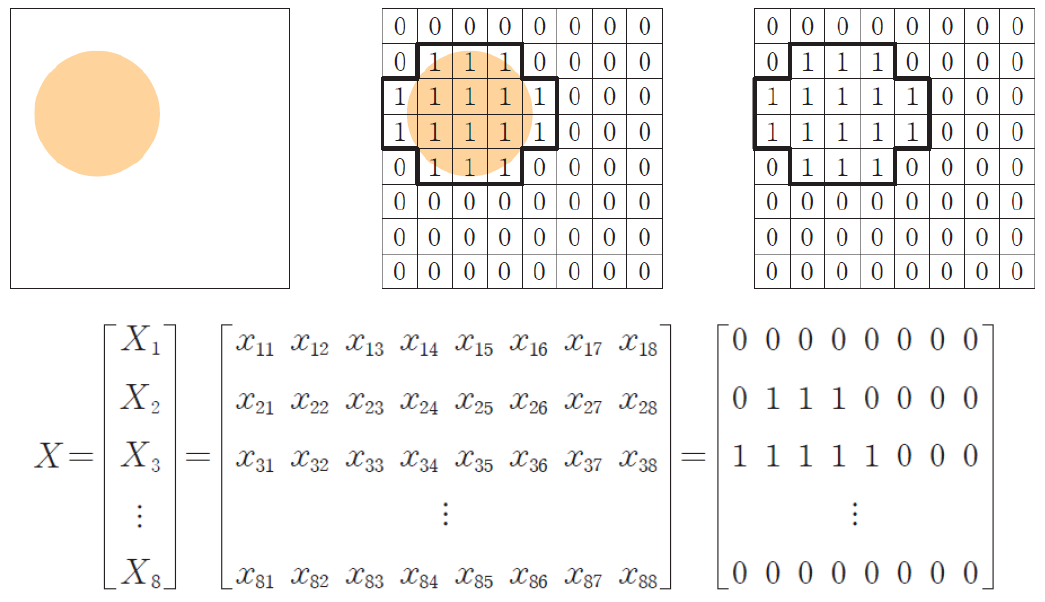
색의 이미지 표현 또한 3색정보(R:Red, G:Green, B:Blue)로 분리하여 3개를 쌓아 놓은 3차원 배열을 이용합니다. RGB라고 많이 들어 보셨을 텐데요, 한의 픽셀마다 R, G, B에 각각 1바이트(8bit)씩 정보가 저장되며, 각각의 색 1바이트에는 0~255까지 256단계의 농도를 표현합니다.
아날로그 이미지를 디지털 이미지로 처리하기위해서는 표본화(Sampling)과 양자화(Quantization)을 거치게 되는데요 그 내용은 다음과 같습니다.
- 표본화(Sampling)은 이미지를 픽셀 단위로 쪼개는 것으로 간격에 따라 고해상도, 저해상도로 구분이 되는 것입니다.
- 양자화(Quantization)은 연속적인 색상의 값은 이산치(양자화 레벨, 화소값)으로 변환하는 것으로 각 픽셀의 밝기 또는 색을 숫자로 표현합니다. 일반적으로 흑백사진은 256레벨(8bit), X선 이미지는 1024레벨(10bit) 입니다.
이미지 필터라고 들어보셨을 텐데요 이러한 이미지 필터링도 이미지 데이터를 처리하는 기법입니다. 윤곽선 추출 필터(Edge Detection Filter), 평균값 필터(Average Filter), 밝기 조절 필터(Brightness Filter), 예술적 필터(Artistic Filter) 등이 있습니다.
3. 오디오 데이터
대기 중의 미세한 기압의 파동을 일으켜 연속적인 크기의 진동으로 인간의 귀에 전달하는 신호가 바로 소리 입니다. 오디오 데이터는 Sine 파형으로 표현되고 진폭이 낮으면 작은 소리, 진폭이 크면 큰소리, 진동수(=주파수)가 낮으면 둔탁하고 낮은 소리, 진동수가 높으면 날카롭고 높은 소리 입니다.

오디오의 아날로그 신호는 잡음이 들어가거나 왜곡 발생이 쉽고 원본이 변형되기 쉬우며 변형된 아날로그 신호를 원상복구하기가 어렵습니다. 그래서 오디오 디지털 신호로 변환하는 것이고 디지털 신호로 변환 시, 잡음이나 왜곡에 강하고 암호화, 필터링, 합성 등을 쉽게 할 수 있습니다. 다만 이미지 데이터와 오디오 데이터 등은 디지털로 변환시 변조가 가능하여 Fake 할 수 있다는 것이 단점이긴 합니다.
- 표본화(Sampling)은 1초 구간을 쪼개어 데이터를 추출하는 작업입니다. 인간이 들을 수 있는 가청 주파수에 따라 모든 신호를 샘플링 할 필요가 없고 1초동안 약 8000개 데이터를 샘플링을 해도 충분하다고 합니다.
- 양자화(Quantizing)은 샘플링에서 추출한 진폭값을 일정한 범위의 디지털값으로 표현하는 과정입니다. 샘플링 데이터를 8bit로 표현한다면 0~255 사이의 값으로 변환되는 것입니다. 양자화로 사용되는 비트수가 클수록 섬세한 데이터를 표현할 수 있으며, 1초에 8000회를 샘플링하여 8bit로 표현합니다. 이것은 64kbps(=64000 bits per second) 입니다.

오디오 데이터의 표현 방식으로는 여러가지가 있는데요 PCM(Pulse Code Modulation), WAV(Waveform Audio Format), MP3(Mpeg-1 Audio Layer-3) 등이 있습니다.
본내용은 구자환교수님의 강의를 기반하였습니다.
https://sites.google.com/site/jahwankoo
Dr. Jahwan Koo's Homepage
Dr. jahwan koo
sites.google.com
공감과 구독은 제게 많은 힘이 될 듯 합니다. !!!
'하얀눈으로 IT' 카테고리의 다른 글
| PowerMockup (1) | 2023.11.03 |
|---|---|
| 비정형 데이터 분석 - 정규 표현식을 이용한 문자 추출 (0) | 2022.09.28 |
| 비정형 데이터 분석 - 텍스트 데이터의 문자열 처리 (2) | 2022.09.28 |
| [파이썬] 파이썬 도구(아나콘다-Jupyter Notebook) (0) | 2022.09.19 |



댓글